最近做到了公共代码抽离到单独仓库的一个工程优化,代码很早就择出来了,但是技术方案迟迟没定,是用 npm 私库?submodule?subtree?🤔🤔🤔
当然看到这篇博客,你就知道我最后肯定选到了 Git subtree 方案,下面就随我一起一步步探索
背景
首先先谈谈开发背景,我司前端项目经过了一系列拆分,现在分为 A 项目、B 项目 pc 端、B 项目移动端、C 项目 pc 端、C 项目移动端…茫茫多,由于当初是从同一个项目仓库里拆出去的,导致当初很多公共依赖的代码,也分别拆到了各个项目里去。
好,问题来了,在 A 项目里定义的公共常量 const common = '向我看齐~' 要改成 const common = '向我看齐!!!' ,那么就需要开发去各个仓库把这段代码都拉齐,慢慢的工作量也会逐渐加大,毕竟如果漏了哪个仓库没复制…@(&#@#@#%^&%。
需求分析
- 多个项目共同开发,但是依赖某些相同的组件
- 在不同项目修改组件要自动同步到所有项目
- 要易用安全,并且尽可能的节省开发过程中的时间,不能增加学习成本或时间成本
技术方案对比
方案一:Npm 私库
在日常开发中我们都 install 过无数个轮子,很好的解决了日常项目工作中可能会用到很多通用性的代码,比如,框架类、工具类以及公用的业务逻辑代码等等,如果 npm 库里有解决方案,我们就可以很开森的用轮子啦,但是 npm 的性质是开源的,总有一些业务是私密程度比较高的或者公司压根就不允许将代码开源的,这时候就需要在公司服务器架设自己的 npm 私有仓库了。
- 优点:
- 和日常 npm install 操作相同,简单易用
- 一次架设成本,后续直接使用即可,人员更换及人员水平变动没有影响
- 组件修改发布后,所有项目都能使用,并且可以指定版本
- 缺点
- 日常开发不便,需要将组件更新发布任何项目更新组件版本后才能看到效果
- 代码提交记录不方便查看
- 更新迭代的速度和主项目需求息息相关,完全不能做到双向推送
方案二:Git Submodule
git submodule 是 Git 官方以前的推荐方案。鉴于我简单的只是查了下文档和大家的讨论博客,对于 Submodule 大家诟病的也很多,什么需要额外配置啦,使用麻烦啦什么的。我看到之后,就直接放弃了这个方案。由于我没深入研究,这里优缺点就不做对比描述了。
ps. 我甚至看到了一篇文章,据理力争的在讲 Submodule 的缺点:why-your-company-shouldnt-use-git-submodules(需科学上网)
像我这种 懒、嫌麻烦 抓紧时间做需求抓紧时间工程优化的人(狗头疯狂保命),当然是直接绕道这个方案了。。。
方案三:Git Subtree
从 Git 1.5.2 开始,Git 新增并推荐使用这个功能来管理子项目。git subtree 是 git 的一条子命令,我们不用关注它具体释义是什么,我们只讨论如何使用它来满足我们的需求。
它可以将我们现在的工程目录中,选择我们指定的文件夹将其变成子仓库,这样这个目录就可以作为一个独立仓库推送到其它项目仓库中,来满足多个项目使用同一个组件库的目的。并且它关联到其他项目指定目录后,每个项目下的组件目录更新推送,其他项目都会收到更新。
- 优点:
- 跟 git 的多人协作同理,关联后一个项目更新所有项目都可以收到推送
- 无需更改现有工程目录
- 组件更新所见即所得,调试效果拉满
- 可以保留这部分代码的历史提交记录
我不管我不管我不管
- 缺点:
- 多人协作,多项目关联,随意性较高,可能改本项目无意间影响了所有项目,因此使用必须给所有成员做说明
- 需要一定 git 相关知识,并且命令较长相对复杂
什么是 Git Subtree
简单来说,git subtree 可以实现一个仓库作为其他仓库的子仓库。下面这个图片比较生动的描述了 subtree 的作用。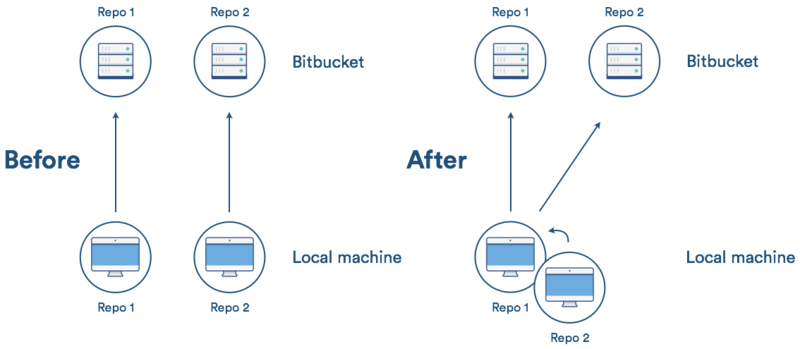
用一句话来描述 Git Subtree 的优势就是:
经由 Git Subtree 来维护的子项目代码,对于父项目来说是透明的,所有的开发人员看到的就是一个普通的目录,原来怎么做现在依旧那么做,只需要维护这个 Subtree 的人在合适的时候去做同步代码的操作。
Git Subtree 的具体使用
在主仓库使用
首先给远程子仓库命名(可选,跟 git 交互类似)
1
git remote add common git@gitlab.xxx.com:your/project.git
添加子仓库
1
git subtree add --prefix=your/lib/location common master
拉取子仓库远程代码
1
git subtree pull --prefix=your/lib/location common master
推送到远程
1
git subtree push --prefix=your/lib/location common master
鉴于我们的项目仓库比较大,所以 subtree 在 push 的时候做代码切割也要很久,我们主项目大概 40000+的 commit 记录,大概 push 了七八多分钟。最后还失败了,简直难用的爆炸。我在等的时候满脑子海绵宝宝的『two thousand years later』….
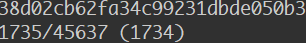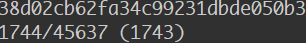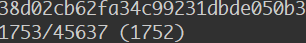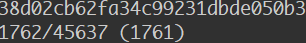
【高阶】分离后推送到远程
1
2git subtree split --rejoin --prefix=your/lib/location --branch temp
git push common temp:master参数说明
- –prefix 之后的=等号也可以用空格
- –squash 意思是把 subtree 的改动合并成一次 commit,这样就不用拉取子项目完整的历史记录。如果不加 –squash 参数,主项目会合并子项目本身所有的 commit 历史记录,加上 –squash 参数是把子项目的记录合成一次 commit 提交到主项目,这样主项目只是合并一次 commit 记录。具体要不要使用这个参数,可以看下面一段的对比
嗯,当代码体积很大的时候,手动 split 代码,只 diff 最新加入的这些 commit,然后 push 即可,友好很多了
在子仓库使用
- 正常建自己的分支,正常开发,正常合并到 master 即可
- 然后去主仓库拉取最新代码
1
git subtree pull --prefix=src/common/ats-client-common ats-client-common master
两种方案对比
- 第一种,新建子仓库自己的分支方法稍微麻烦些,需要更多的
git subtree知识,但是如果只是操作 master,开发体感上更接近于原来的开发方式,只是在主仓库需要时多了额外的 推送/拉取 操作,不需要去额外关注维护子仓库。 - 第二种,直接去子仓库创建自己的分支,然后 merge 进 master,主仓库再去拉取最想子仓库代码,增加了开发时间成本,也需要去额外维护子仓库
- 实际开发我更推荐第一种方案,因为我们是公共代码,更多的是新增的操作,而不是改,大家都去 master 上操作未尝不可,冲突不会太大。不过两种方法各有利弊,哪种方案都可行。
- 第一种,新建子仓库自己的分支方法稍微麻烦些,需要更多的
关于 git subtree 的–squash 参数
–squash 是用来把所有的 commit 记录合并的,这样子仓库看起来很整洁。
关于–squash 参数要不要用的问题,先说结论:用不用都行,但是用就一直用,不用就一直不用。
| 优点 | 缺点 | |
|---|---|---|
| 用–squash | 子项目仓库 commit 记录整洁干净 | 主项目 pull 的时候解冲突,解到地老天荒 |
| 不用–squash | 主项目 pull 的时候,很顺利,基本没冲突 | 主项目 pull 子仓库代码的时候,会把之前的 commit 记录带进来,”污染了”主项目 |
对比下来,我选择了不用–squash。毕竟解冲突实在是麻烦。
这张图,光是看着就让人头秃。。。
👻 当然更具体的原因分析可以参考 这篇文章
【注意】实际开发踩坑
上面把 subtree 说的非常好用的样子,但实际开发上遇到坑实在是有些多,大家一定要踩完再决定引不引入使用,不然就像我一样一不小心就把小伙伴们开发环境的代码搞崩了,唉
- 确保你们的公共代码只做增加,不做修改,或者能保证向下兼容。 不然你在依赖仓库改动了部分代码,别的小伙伴准备拉取最新的来进行开发,结果因为改了之前的代码导致不兼容,就只能继续再改。。
- 依赖仓库开发环境的代码会被误带到线上 因为 subtree 的分支管理很难受,所以基本上大家都会直接使用 master,那开发环境大家也都在 subtree 的 master 上操作,别的人在把主项目代码提交到 master 时,会把那部分代码也带上去
- push 和 pull 的时候,反反复复解冲突 开发体验很差,不知道为什么虽然作为 git 的功能,但是使用上解冲突能力很差,基本上每次操作都会有冲突
- commit 信息很多 即使用了 squash 参数,每次拉取代码也都最少会生成两条 commit,主项目的 commit 列表会被污染
- debug 难度增加 不知道大家都用的子仓库哪个时态的 master 代码,导致可能查 bug 的时候查不到。
- 限制更新频率 subtree 本身不限制更新频率,但是当实际开发时更新频率过高,需要不断的和小伙伴同步这些消息,不然解冲突的时候会把别人的代码搞丢…所以更新频率最好不要太快